自建 LocalAI,本地使用 ai 模型 - 聊天機器人
環境建置
確定環境中已經建置好 Docker 以及 docker-compose,或者點擊這裡來安裝所需要的依賴,windows 環境可以使用 WSL
LcalAI
LocalAI 是基於 openai api 的規範下開發的,優點是如果在條件受限下甚至不需要顯卡或是 cuda 加速,純 cpu 也可以使用多種模型,並直接轉換為 REST API,我們這邊按照官網的引導準備兩個文件
docker-compose.yml.env
docker-compose.yml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
version: "3.6"
services:
api:
image: quay.io/go-skynet/local-ai
tty: true
ports:
- 8080:8080
env_file:
- .env
volumes:
- ./models:/models
- ./images:/tmp/generated/images
- ./cache/:/root/.cache
command: ["/usr/bin/local-ai"]
.env
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
## Set number of threads.
## Note: prefer the number of physical cores. Overbooking the CPU degrades performance notably.
THREADS=4
## Specify a different bind address (defaults to ":8080")
ADDRESS=0.0.0.0:8080
## Default models context size
CONTEXT_SIZE=51200
#
## Define galleries.
## models will to install will be visible in `/models/available`
GALLERIES=[{"name":"model-gallery", "url":"github:go-skynet/model-gallery/index.yaml"}]
MODELS_PATH=/models
## Enable debug mode
DEBUG=true
## Disables COMPEL (Diffusers)
COMPEL=0
BUILD_TYPE=openblas
這邊只建議更動 THREADS 去因應 host 機的 CPU 物理核心,非邏輯核心,以我測試的 N100 來說,總共有 4 個物理核心,所以這邊設置為 4,GALLERIES 為作者開發的模組庫,保留不變即可
接下來我們直接啟動 LocalAI 服務
1
docker-compose up -d
稍等一段時間後,等到容器啟動,然後我們下
1
docker-compose logs -f
去追蹤 log,發現有大量的 200 readyz 的 GET 請求,代表健康檢查已經通過,我們就可以開始使用了
Mistral (LLM)
接下來我們要開始邁入使用的第一步,建立自己的聊天機器人,測試了一些模型後發現,Mistral 這個 LLM 模型對中文的支持,還有回應的準確度挺不錯的,相關的介紹可以看 這邊,我們會依照下面幾個步驟來導入自己的模型並且使用
新增模型- 撰寫
yaml - 重啟
LocalAI
沒錯,就是這麼簡單,LocalAI 已經幫你把最複雜的部份都處理完了
下載模型(選用)
我們找到 Mistral 的ft 模型,可以看到介紹模型依照輕量到重型依序排序下來,我們要自己依照硬體資源去取捨
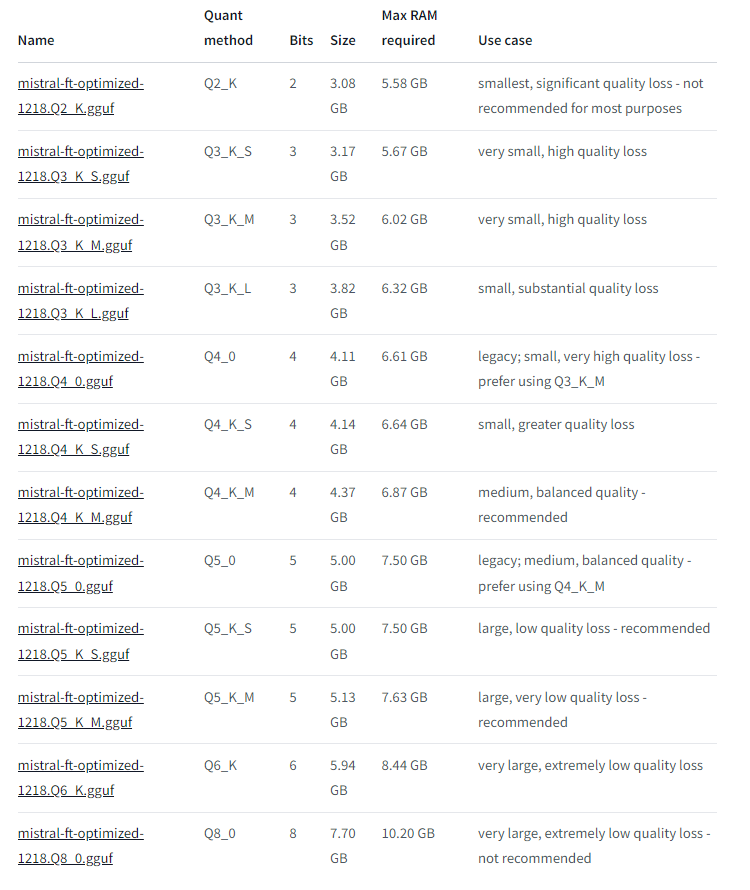
這邊選擇 mistral-ft-optimized-1218.Q4_K_M.gguf 這個 model,進入 models 資料夾後,執行以下指令去下載
1
wget https://huggingface.co/TheBloke/mistral-ft-optimized-1218-GGUF/resolve/main/mistral-ft-optimized-1218.Q4_K_M.gguf?download=true -O mistral-ft-optimized-1218.Q4_K_M.gguf
新增 yaml
在前面提到的模組範本中,我們可以直接將這份範本使用模組導入
1
curl http://localhost:12345/models/apply -H "Content-Type: application/json" -d '{ "id": "model-gallery@mistral" }'
接著在 models 資料夾下你就會看到三個檔案
mistral-7b-openorca.Q6_K.ggufmistral.yamlchatml.tmpl
你有自己下載模型,則需要將 mistral.yaml 下方的,model 替換為 mistral-ft-optimized-1218.Q4_K_M.gguf,或者直接按照原檔中的使用
重啟 LocalAI
最後我們回到 docker-compose.yml 所在的上一層目錄,執行
1
docker-compose restart
如果到這邊都執行正確的話,我們就可以用 智能客服 這個目標開始測試看看了
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
curl --location 'http://127.0.0.1:8080/v1/chat/completions' \
--header 'Content-Type: application/json' \
--data '{
"model": "mistral",
"messages": [
{
"role": "system",
"content": "請你扮演一個專門負責退貨的客服,安撫客戶情緒,並避免客戶退貨,回答請盡量用繁體或簡體中文"
},
{
"role": "user",
"content": "你們的產品真夠爛的 我要退貨"
},
{
"role": "assistant",
"content": "您可以洽詢您購貨的地區客服中心,他們會為您處理退貨事宜。 如果您不知道您購貨的地區客服中心,請提供您的購貨單號或購貨日期,我們將幫您查詢。"
}
],
"temperature": 0.2
}'
可以看到我這邊放了三個角色,system、user、assistant,其中 system 有著 prompt 的作用,好的 prompt 對於最終結果非常重要,可以在這邊規範輸出結果,user 指的就是使用者的輸入,assistant 就是上一次 response 結果,結合在一起就是一個 context 的概念,讓整個對話具有一致性
按照順序的話會是這樣子的
定義了一個 prompt,扮演智能客服的角色,並將使用者的輸入 你們的產品真夠爛的 我要退貨 打進去 api
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
curl --location 'http://127.0.0.1:8080/v1/chat/completions' \
--header 'Content-Type: application/json' \
--data '{
"model": "mistral",
"messages": [
{
"role": "system",
"content": "請你扮演一個專門負責退貨的客服,安撫客戶情緒,並避免客戶退貨,回答請盡量用繁體或簡體中文"
},
{
"role": "user",
"content": "你們的產品真夠爛的 我要退貨"
}
],
"temperature": 0.2
}'
然後得到了這個 response
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
{
"created": 1709895183,
"object": "chat.completion",
"id": "de2a8085-5667-4047-be19-1648bfc01648",
"model": "mistral",
"choices": [
{
"index": 0,
"finish_reason": "stop",
"message": {
"role": "assistant",
"content": "您可以洽詢您購貨的地區客服中心,他們會為您處理退貨事宜。 如果您不知道您購貨的地區客服中心,請提供您的購貨單號或購貨日期,我們將幫您查詢。\n"
}
}
],
"usage": {
"prompt_tokens": 0,
"completion_tokens": 0,
"total_tokens": 0
}
}
最後將這句 response 帶入原本的 request 中,然後將下一句使用者說的話承接於 assistant 之後,就是一次完整的對話啦
接下來的幾個篇章會介紹
txt2img(文字轉圖片)tts(文字轉語音)gpt vision(圖片辨識)