Elasticsearch,先把搜尋這件事做好,再談分析與向量

前言
我自己第一次碰 Elasticsearch 的時候,老實說有點高估它了。
那時候覺得它既然可以全文搜尋、可以分析、可以做聚合,甚至現在官方也把它講成 search、analytics、vector database 三合一,看起來就像什麼都能做。1
但真的用下去後,我反而覺得最重要的一句是:
先把搜尋這件事做好,再慢慢去碰進階功能。
這篇我會用比較適合新手的角度重講一次,包含為什麼要用它、最簡單怎麼起來、分析器到底在幹嘛,以及我自己覺得最容易踩的地方。
Elasticsearch 到底適合什麼場景
先不要一開始就想成它是萬用資料庫。
對我來說,它最適合的場景其實很單純:
- 你要做全文搜尋
- 你想做模糊比對、分詞、權重排序
- 你會查詢大量文件資料
- 你後面可能還想加聚合、過濾、簡單分析
如果你只是要一般 CRUD,而且查詢條件固定、結構也很單純,那很多時候 MySQL / PostgreSQL 就夠用了。
現在官方怎麼定位 Elasticsearch
Elastic 現在官方首頁很直接,把它定位成:
- distributed search and analytics engine
- scalable data store
- vector database
而且最近的文件也把 Query DSL、ES|QL、aggregations、ingest pipeline、mapping、data lifecycle 都擺得很前面。1
這代表它已經不是只做關鍵字搜尋,而是整個資料搜尋與分析平台。
不過如果你是剛開始碰,我會建議還是先只理解三個東西:
- index
- mapping
- analyzer
這三個吃透了,後面才比較不容易亂。
最簡單的本機起手式
如果你只是想先玩一下,我會建議用單節點 docker 起來就好。
1
2
3
4
5
6
7
8
9
10
services:
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:9.1.4
container_name: elasticsearch
environment:
- discovery.type=single-node
- xpack.security.enabled=false
- ES_JAVA_OPTS=-Xms1g -Xmx1g
ports:
- '9200:9200'
然後啟動:
1
docker compose up -d
先不要急著接 Kibana,也不要一開始就研究 cluster。你只要先確認這台東西起得來。
1
curl http://127.0.0.1:9200
有回 JSON,就代表第一步過了。
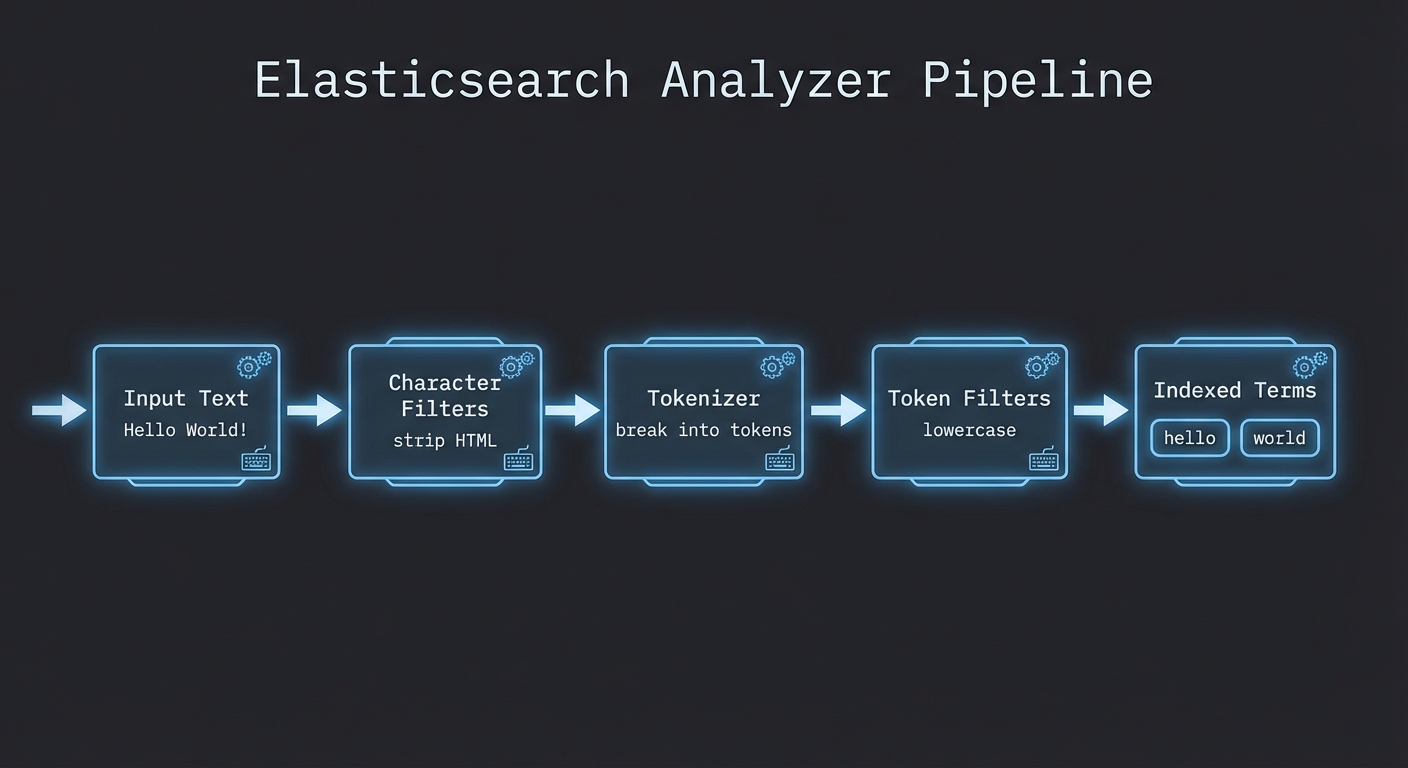
為什麼 analyzer 這件事這麼重要
很多新手第一次碰 Elasticsearch,會覺得最難的是 query。實際上我覺得更常出問題的是 analyzer。
因為搜尋結果好不好,很多時候不是 query 寫得多花,而是進資料的那一刻有沒有切對。
官方現在也把 ingest pipeline、mapping、search language 這些文件放得很前面,不是沒有原因。1
你可以把 analyzer 想成:
- 資料進來先怎麼拆
- 要不要轉小寫
- 要不要去除符號
- 中文、英文、數字要怎麼切
如果這一步沒設好,後面你查得再漂亮也沒什麼用。
最值得先學會的兩件事
1. mapping 不要亂放
如果你把所有欄位都丟成預設型別,前期可能很爽,後期通常會開始痛。
像是:
- 你明明要做全文搜尋,結果欄位被當 keyword
- 你明明只要精準比對,卻把欄位設成 text
新手最實用的做法,就是先分清楚:
text:用來全文搜尋keyword:用來精準過濾、排序、聚合
2. _analyze 很值得常用
如果你根本不知道 analyzer 有沒有照你想的切詞,最快的方法就是直接測。
1
2
3
4
5
6
curl --location 'http://127.0.0.1:9200/_analyze' \
--header 'Content-Type: application/json' \
--data '{
"analyzer": "standard",
"text": "Elasticsearch is very useful for full text search"
}'
這個 API 很適合新手,因為你可以立刻看到資料被怎麼拆。1
近兩年的變化,我會怎麼看
現在 Elasticsearch 的文件越來越強調這幾塊:
ES|QL- vector / semantic search
- ingest pipeline
- data lifecycle
這些都很有用,但如果你是剛開始學,我反而會建議先不要被這些大功能拉走。
因為你真正第一個會遇到的,通常還是:
- 搜尋結果為什麼怪怪的
- analyzer 怎麼調
- mapping 怎麼定
- keyword 跟 text 什麼時候用
我自己最常給新手的提醒
1. 不要把 Elasticsearch 當成主要交易資料庫
它很強,但不是每種資料都該往裡面塞。
2. 先用小資料集測語意,不要一開始就大量灌資料
因為你很可能前面 mapping 就定錯。
3. 搜尋品質通常不是 query 一行解決,而是整條 pipeline 的問題
這也是為什麼我一直說 analyzer 比你想像中更重要。
我的感想
如果要我用一句話總結 Elasticsearch:
它很強,但強的前提是你先把搜尋基礎觀念弄對。
我自己現在反而不會太快把它神化成「全能資料平台」,而是更願意把它看成一個很成熟、很可靠的搜尋引擎,再慢慢往分析、向量和進階功能擴出去。
這樣學起來會紮實很多。